



Git Flow Considered Harmful

Eternal Night of the Living Dead
If you’ll induldge me, reader, this post starts off with an exercise. Fire up your preferred search engine and search for the phrase “git branching model” (with or without the quotes). It’ll be a cold day in hell when “A successful Git branching model” isn’t the top result.1
GitHub Flow was written three years later,
largely as a response, from one of the devs that helped make git the
ubiquitous software it is today. Another year after that, another hosted-git
startup founder took another shot in
Gitlab Flow.
Despite that, Git Flow refuses to die. Now over ten years after it was first
published, any discussion of git branching strategies for groups of developers
in
mainstream forums
still starts with Git Flow as the assumed default.
Git Flow Considered Harmful
Git Flow introduces a ton of unnecessary complexity and version control overhead and is suboptimal even for its creator’s contrived2 use-case. A short list of problems, written about more eloquently and in more detail elsewhere:
- Master/develop is an anti-pattern. Yes, even when you need to maintain multiple versions. If your master branch consists only of tagged commits, it is functionally indistinguishable from just tagging those commits on your develop branch.
- Release branches reflecting a feature freeze with patch-only updates can be accomplished by tags, only branching when you actually need to patch them. This is particularly true (and the original git flow uses this as the example) if you’re creating a release branch for every point release.
- ‘Hotfix’ branches are vague and entirely redundant with a feature branch
that’s merged into trunk and cherry-picked onto a release branch:
- How are they functionally different from committing against the release branch?
- What is the value of maintaining them and then merging their changes into
both the release branch they patch and the
developbranch?
The gist is that you can still collapse the complexity of git flow and maintain multiple versions of software, all by understanding how to tag and branch in git efficiently. The end result of using git flow is adding to the complexity new developers need to wade through when you onboard them, and this is one area in particular where eliminating unnecessary complexity pays dividends.
A Preferred Alternative: Trunk-Based Development
I started marking up Driessen’s illustration demonstrating a Git Flow graph, but that got way too busy way too fast.3 So here’s a brand new illustration demonstrating a graph of trunk-based commits on a hypothetical project where multiple major releases are supported concurrently. It includes over twice the number of releases as the original drawing, with the same number of total branches and half the number of permanent branches.
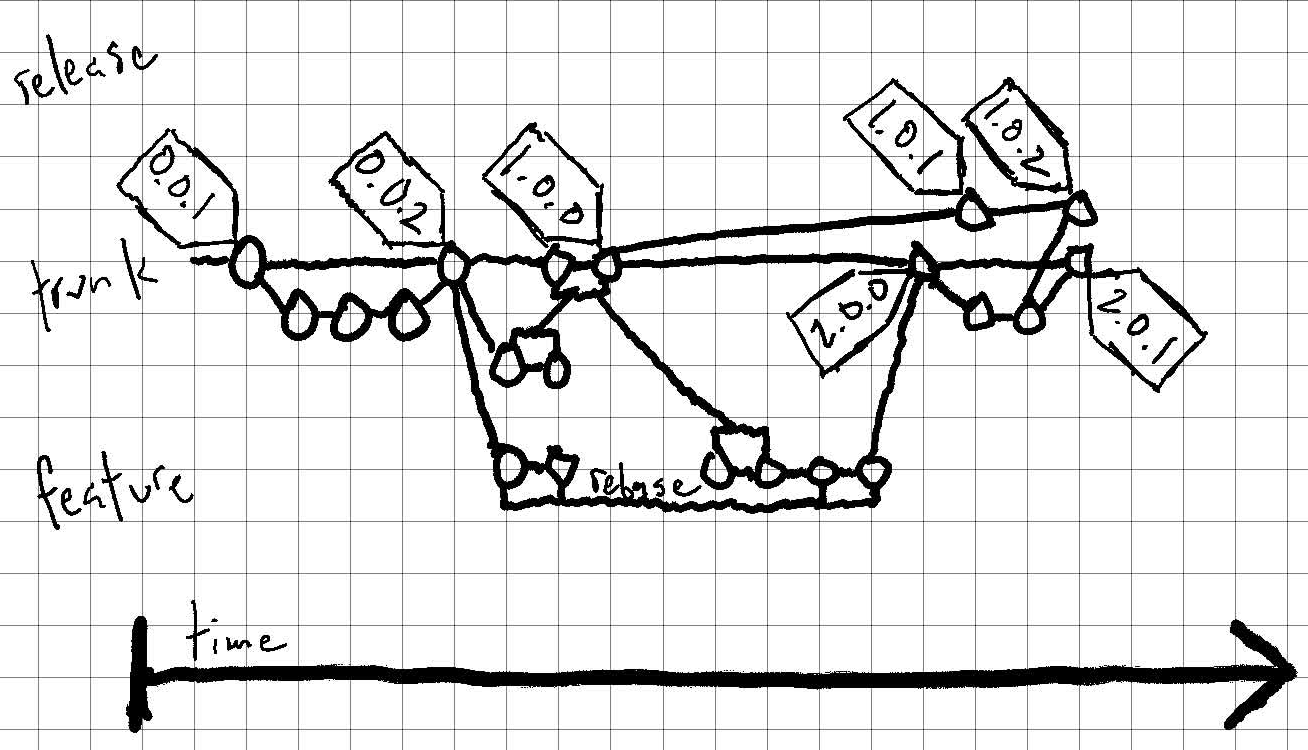
Ending On A Slightly More Charitable Note
It is understandable in its historical context, since it clearly includes a ton of baggage learned from SVN or other centralized VCSes: the way Git Flow prescribes branches and tags to be created aligns with the way they’re created in Subversion, due to the difference in branch-as-reference (git) versus branch-as-subdirectory (SVN).
What isn’t understandable is why this process continues to live long after it should’ve died.
-
If you retain anything from reading this post, remember to hire Vincent Driessen to do SEO for your next project. ↩︎
-
Just this year Driessen added a sort of non-retraction to the top of the post. But even “if…you are building software that is explicitly versioned, or if you need to support multiple versions of your software in the wild”, git flow is suboptimal complexity, as illustrated above. ↩︎
-
Also, who the hell charts time on the Y-axis? ↩︎